AI-Skills
Digital History, Institut für Geschichtswissenschaften
Scholarly Makerspace

![]()
Torsten Hiltmann
Professur für Digital History (seit 2020)
Institut für Geschichtswissenschaften

Ein Lernort für digitale Werkzeugkompetenz in den Geistes- und Kulturwissenschaften
“Future e-Research Support in the Humanities" (DFG, 2022–25)
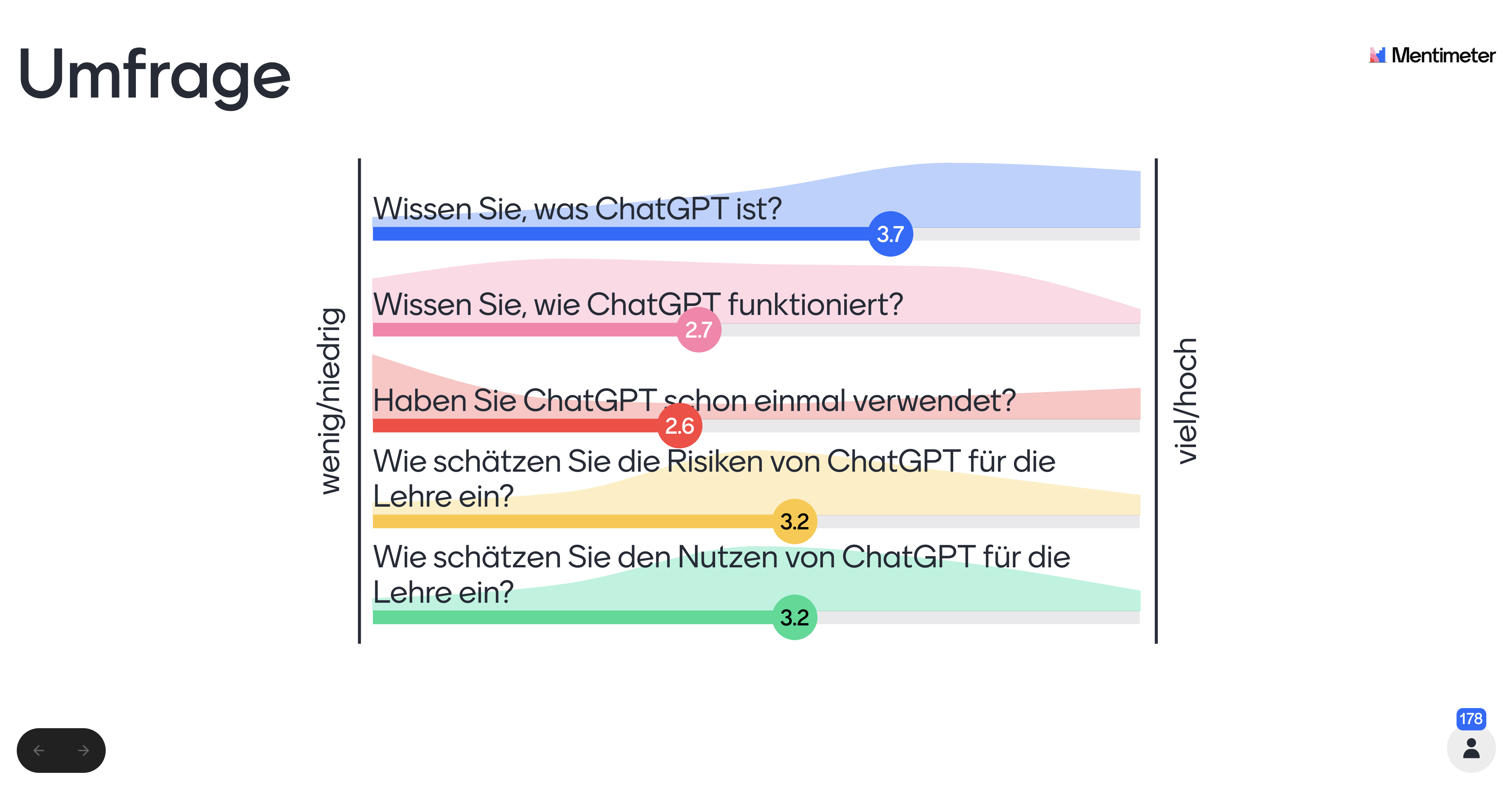
Wir haben eine kleine Umfrage zu ChatGPT vorbereitet
Wir haben ein Miroboard für das weitere Vorgehen vorbereitet

Königin - weiblich = KönigArzt + weiblich = KrankenschwesterIt is a riddle… wrapped in a mystery…inside an enigma
Winston Churchill
LLMs sind Blackboxes…
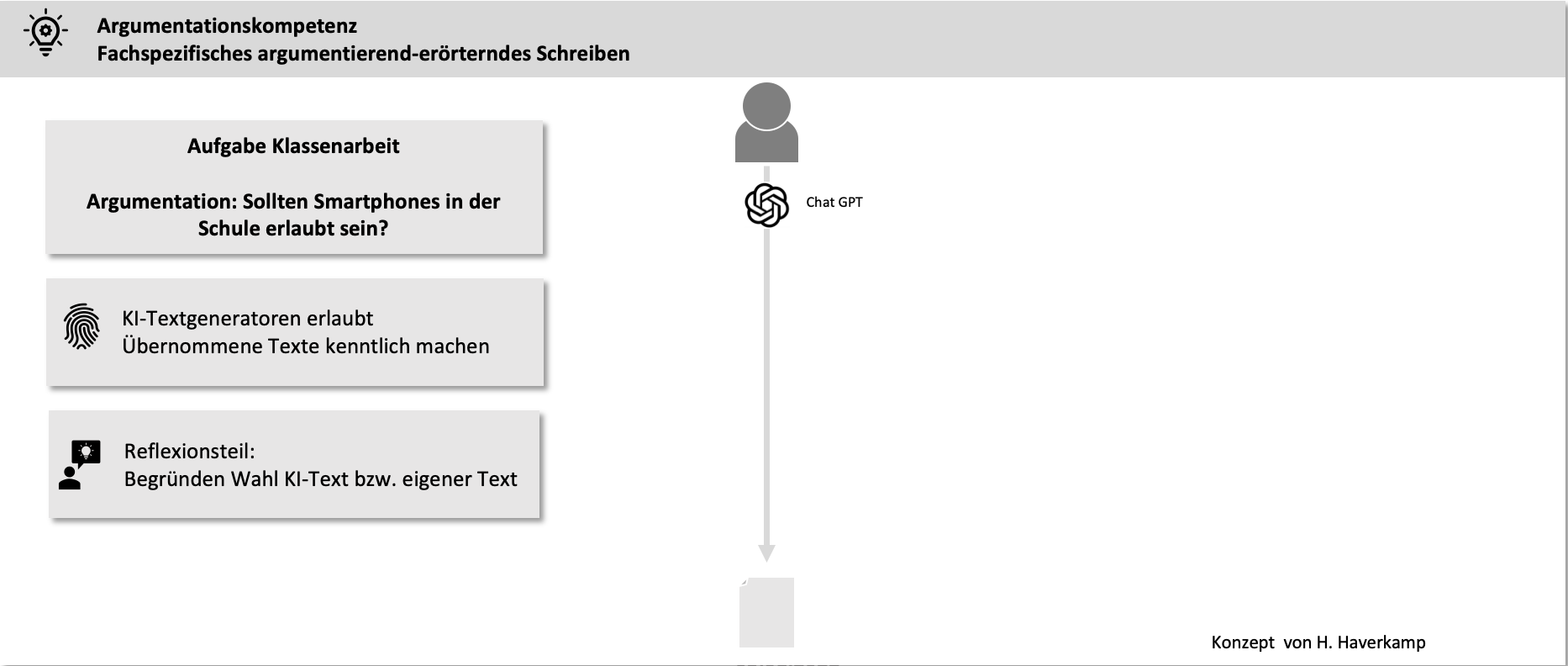
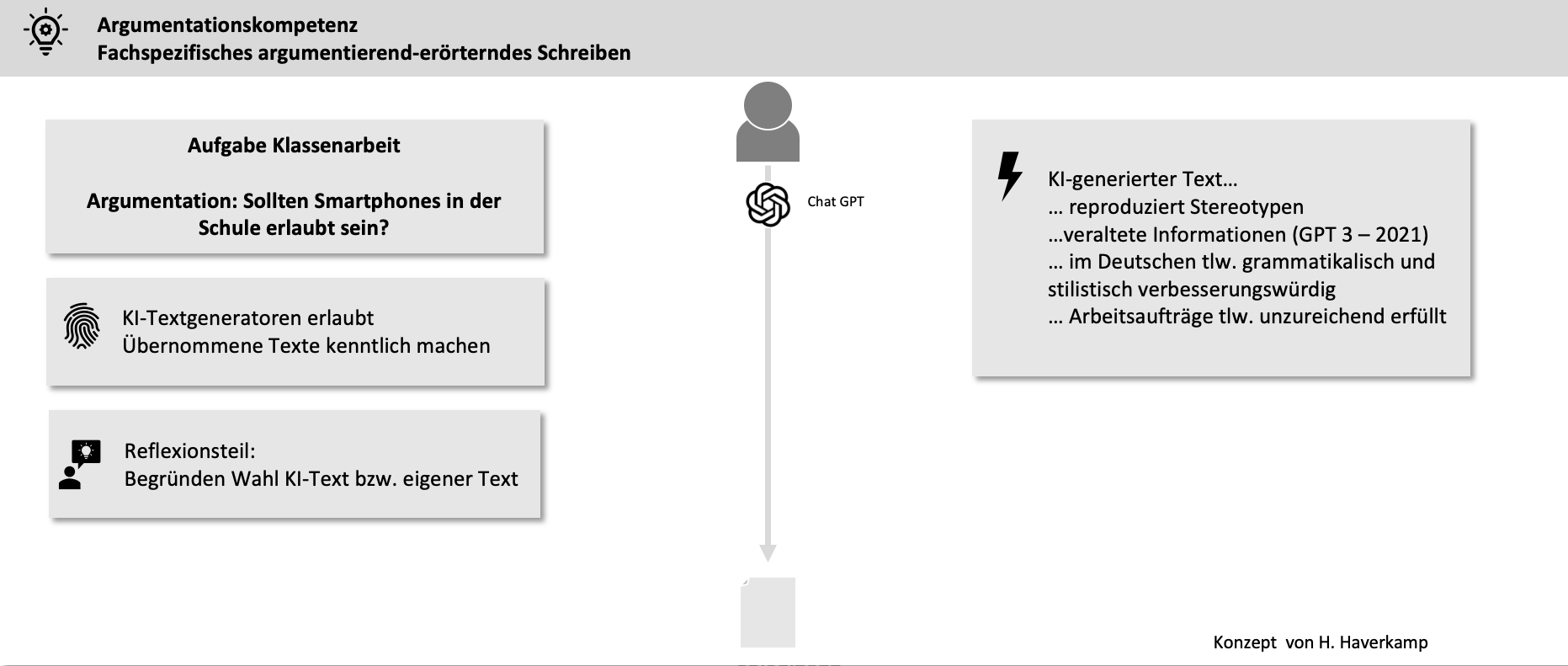
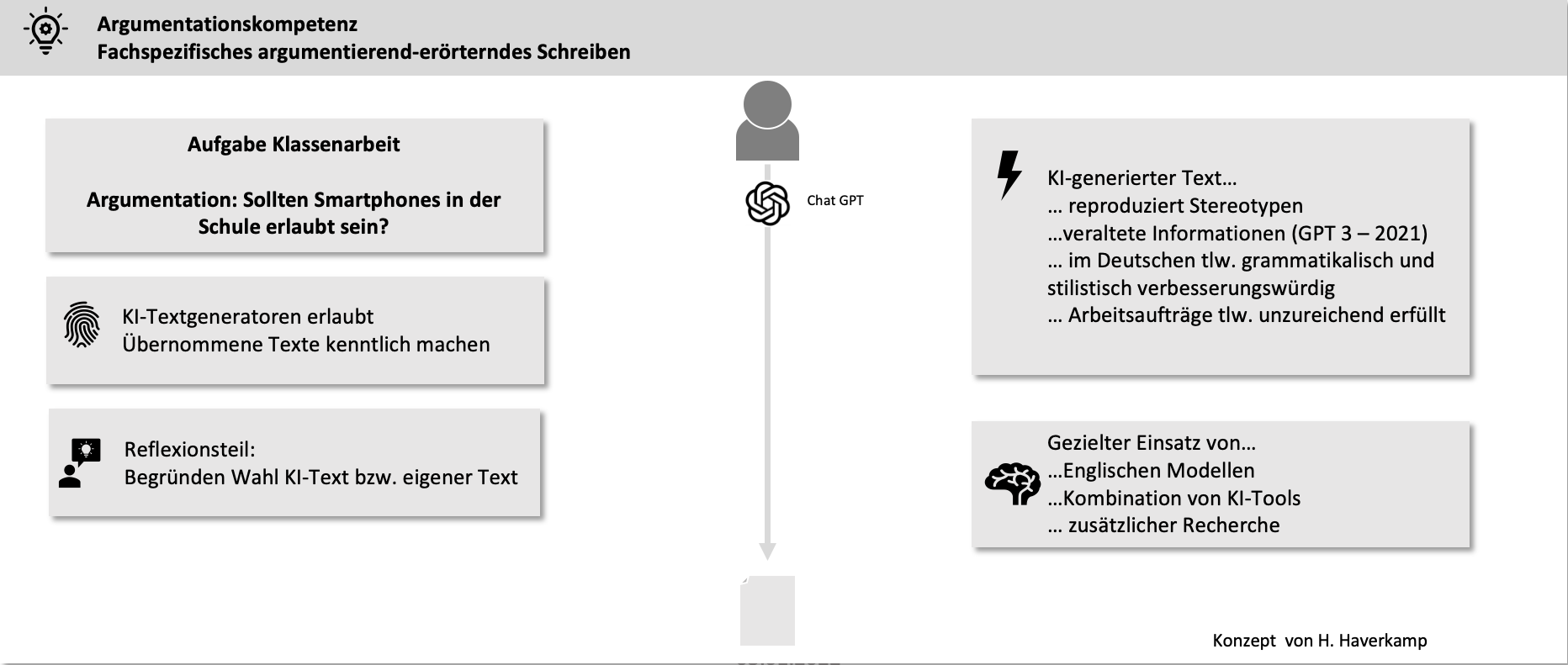
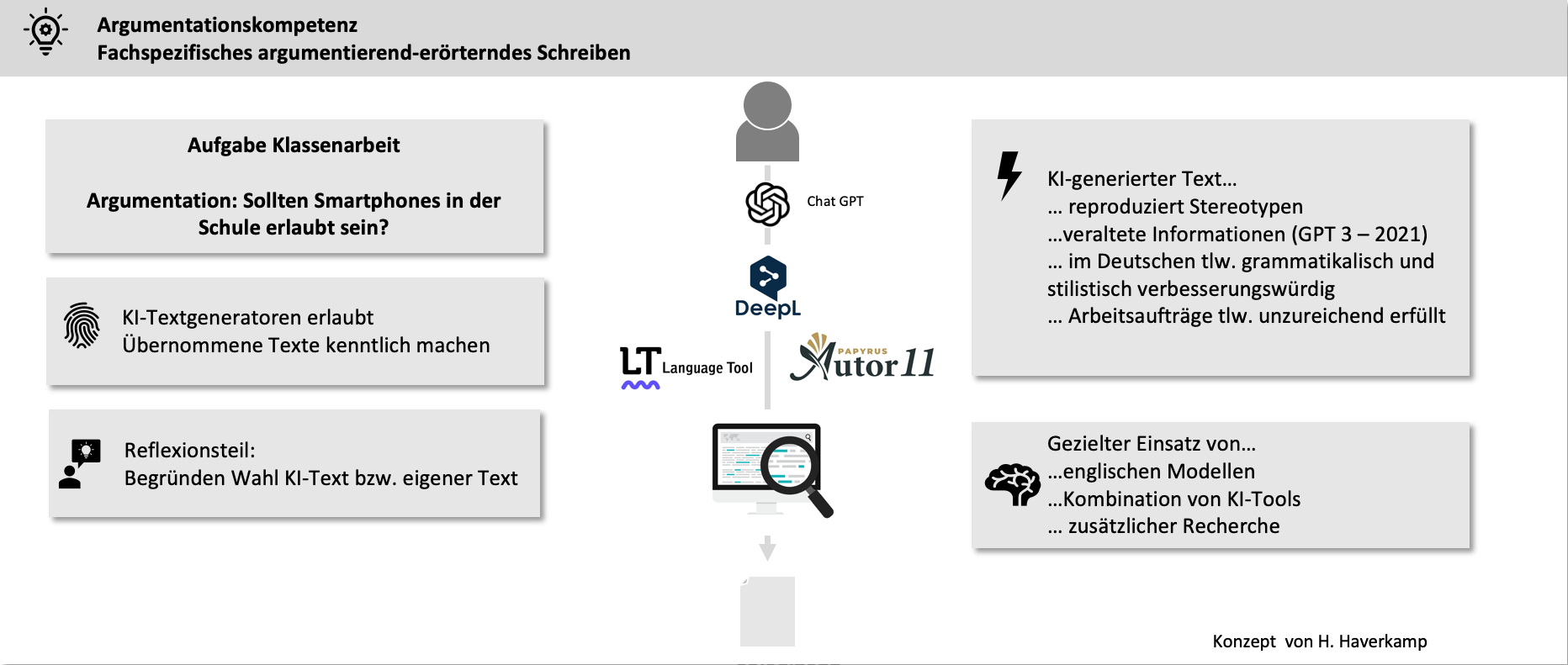
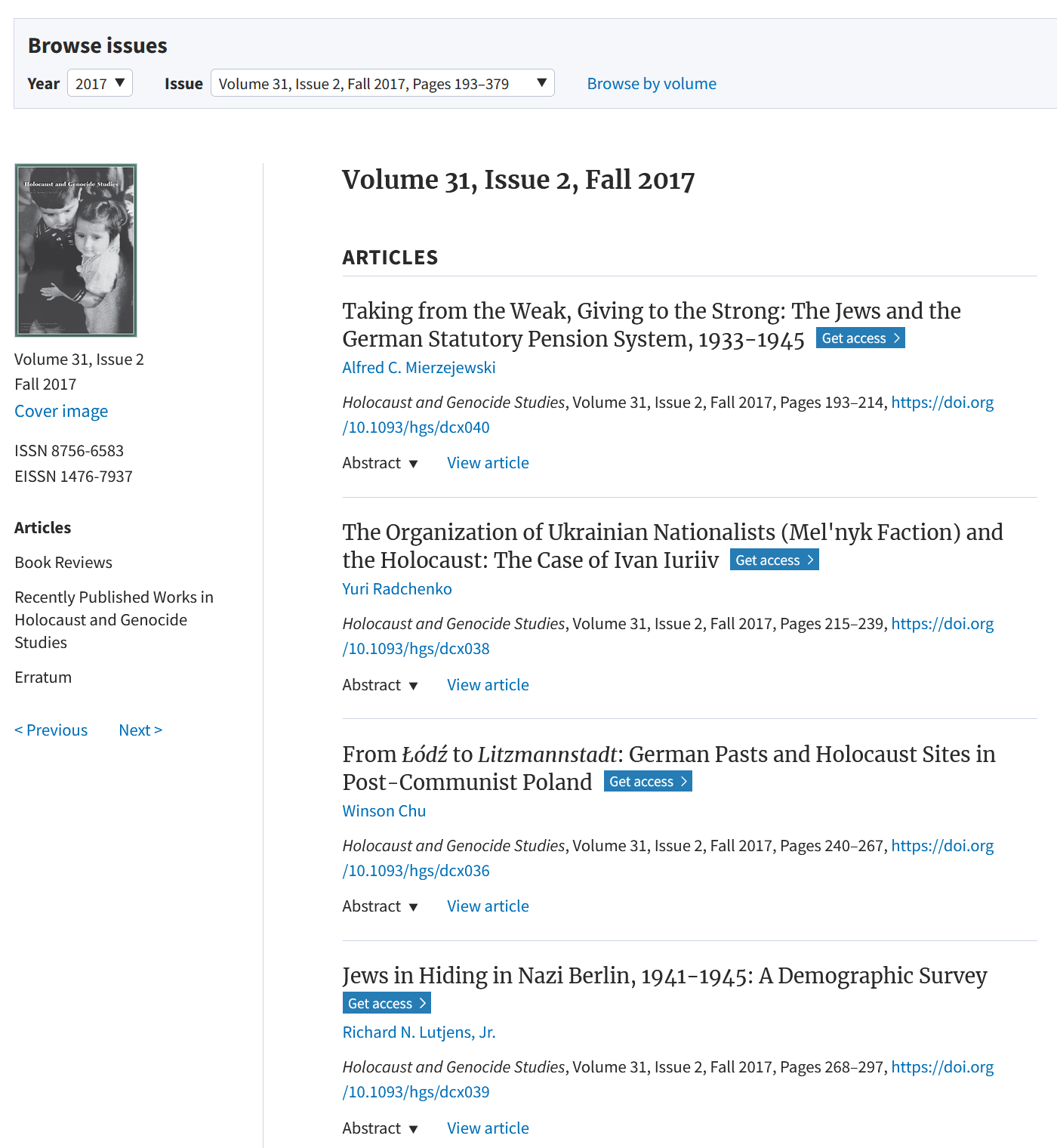
Write a summary in scientific style on the role of Topf & Sons in Auschwitz, citing literature and sources.
Topf & Sons was a German engineering firm that played a significant role in the Holocaust as a supplier of crematoria and incineration equipment to the Auschwitz concentration camp, where millions of Jews and other minorities were murdered. The company profited economically from the systematic extermination of Holocaust victims …
ChatGPT


Hier noch einmal die Ergebnisse unserer kleinen Umfrage zu ChatGPT
Hier noch einmal unsere gemeinsames Miroboard zum weiteren Vorgehen